顔妻です。
クラスター分析についてご紹介です。教師なし学習のひとつとして有名な手法のひとつで、目的変数を設定せずに集団の傾向を探していくときに利用したりします。今回は使い方を中心に記載します。
今回利用するデータとか目的
Rに標準で入っているirisのデータを利用します。今回はとりあえず使えるようになることがメインです。このデータはアヤメの種類ごとに花びらの大きさが載っています。葉の種類から種類を推定してみましょう。
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5 | 3.6 | 1.4 | 0.2 | setosa |
学習した結果と元々の分類を使って作図してみましょう。色をうまく指定できなかったのですが、分類自体はかなり近しいものができているようです。
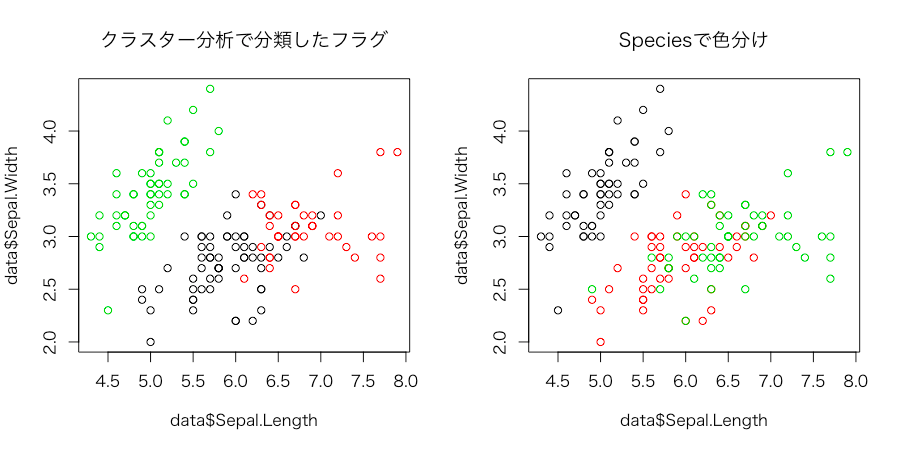
それではどれだけ一致してるかをクロス集計で確認してみましょう。
| 1 | 2 | 3 | |
| setosa | 0 | 0 | 50 |
| versicolor | 48 | 2 | 0 |
| virginica | 14 | 36 | 0 |
大体一致しているようです。「virginica」があまり分類できていないような気もします。今回使ったクラスター分析は非階層クラスター分析なので何回か繰り返すと一致するかもしれません。
まとめ
分類に利用している細かい手法にはほとんど触れていませんでしたが、データを群わけしてみたいときに役立つと思いますし、そのわけたものから示唆を導くのがアナリストやサイエンティストの腕の見せ所ではないしょうか。