Rで分散分析を行う時のやり方について説明します。
一元配置分散分析
要因要素毎の平均値に対して、この要因要素の効果影響があったかどうかを調べるときに利用します。
こちらは以下のサイトを参考に実施しています。
# データの読み込み
d <- read.csv('https://raw.githubusercontent.com/logics-of-blue/website/master/020_basic/20201219_%E5%88%86%E6%95%A3%E5%88%86%E6%9E%90%E3%81%AE%E5%9F%BA%E7%A4%8E/data.csv')
# 分散分析用に回帰分析を実行
anova_lm <- lm(formula = weight ~ food,data = d)
# 分散分析の結果を表示
anova(object = anova_lm)
# Analysis of Variance Table
#
# Response: weight
# Df Sum Sq Mean Sq F value Pr(>F)
# food 2 64 32 16 0.02509 *
# Residuals 3 6 2
# ---
# Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1
# P値の結果を表示
1- pf(df1 = 2,df2 = 3,q = 16)
# [1] 0.02509457二元配置分散分析
2要因以上の効果を要因要素毎の平均値に対して、この要因要素の効果影響があったかどうかを調べるときに利用します。
対応あり/対応なしの違いは以下です。
- 対応ありが対象とするサンプルが繰り返し利用される場合。被験者が同じ場合などのケース。(実験計画で多いパターン)
- 対応なしがサンプルや被験者が繰り返し利用されていない場合。
対応なし
d_2 <-
data.frame(
aji = c(6,4,5,3,2,10,8,10,8,9,11,12,12,10,10,5,4,2,2,2,7,6,5,4,3,12,8,5,6,4),
ondo = factor(c(rep("冷蔵庫",15),rep("常温",15))),
meigara = factor(rep(c(rep("イカアン",5),rep("ボスビッグ",5),rep("ビビッテル",5)),2))
)
# 分散分析の実行
summary(aov(aji~ondo*meigara))
# Df Sum Sq Mean Sq F value Pr(>F)
# ondo 1 67.5 67.50 21.316 0.00011 ***
# meigara 2 155.0 77.50 24.474 1.61e-06 ***
# ondo:meigara 2 15.0 7.50 2.368 0.11515
# Residuals 24 76.0 3.17
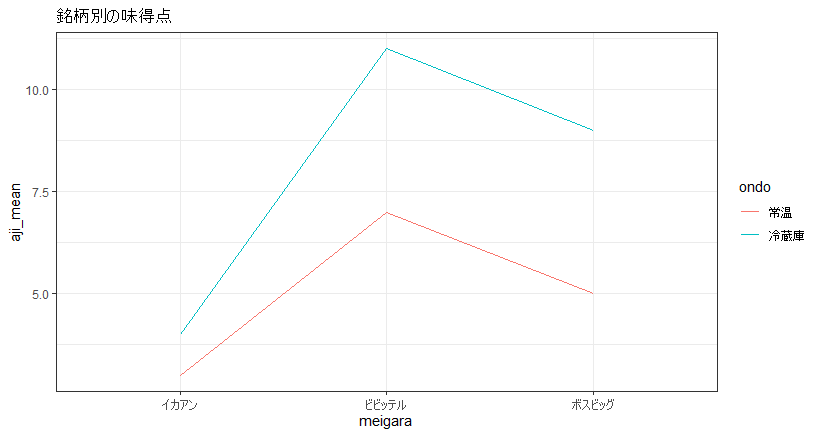
# Signif. codes: 0 ‘’ 0.001 ‘’ 0.01 ‘’ 0.05 ‘.’ 0.1 ‘ ’ 1データの可視化を行って、概観も掴んでおきます。可視化した段階で冷蔵庫に入っていて、かつ、ビビッテルの味の評価がよさそうにみえます。
theme_set(theme_bw())
d_2 %>%
group_by(ondo,meigara) %>%
summarise(aji_mean = mean(aji)) %>%
# spread(ondo,aji_mean) %>%
ggplot(aes(x = ondo,y = aji_mean,group = meigara,col = meigara)) +
geom_line() +
ggtitle('温度別の味得点')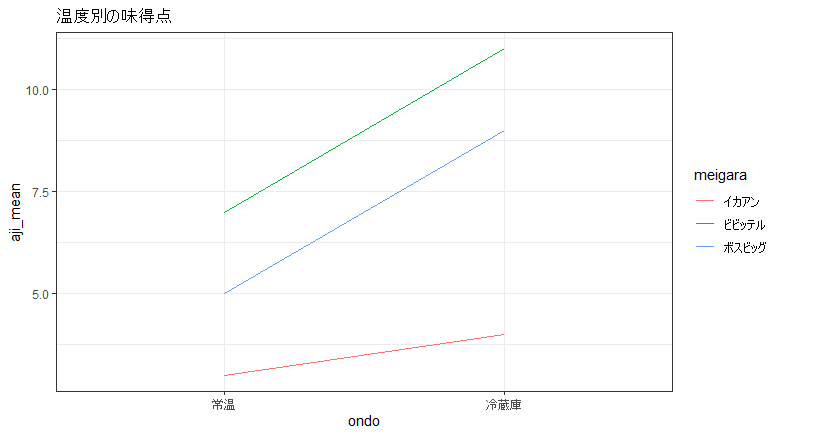
d_2 %>%
group_by(ondo,meigara) %>%
summarise(aji_mean = mean(aji)) %>%
# spread(ondo,aji_mean) %>%
ggplot(aes(x = meigara,y = aji_mean,group = ondo)) +
geom_line() +
ggtitle('銘柄別の味得点')