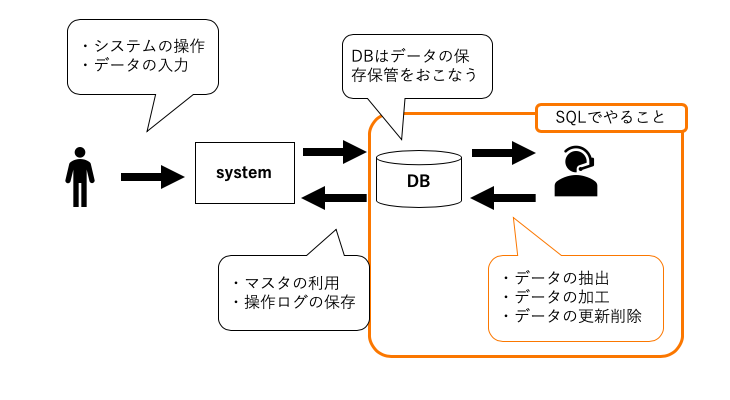
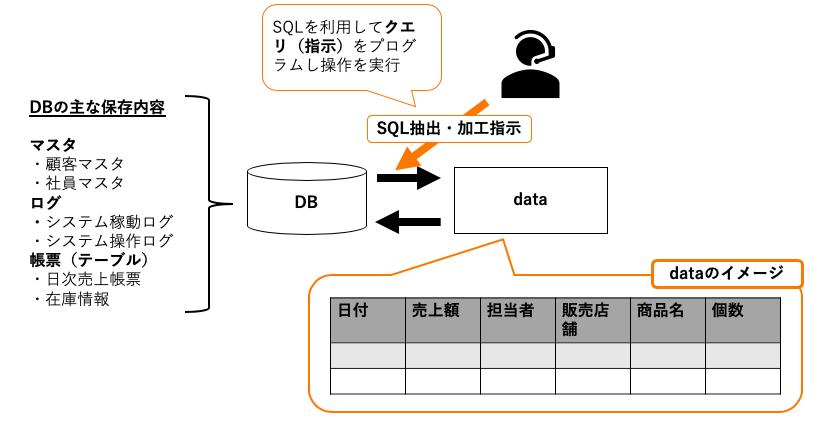
顔妻です。
Rで集計といえばdplyrです。SQLよりも少ない行数でSQLの感覚で集計できる本当に便利なlibraryです。まずはどんなことができそうか参考にしてみてください。
dplyrの関数
| 関数名 | 利用用途 |
| %>% | パイプ演算子。作業を引き継いで実施するときに利用。SQLのサブクエリ的な挙動も可能。 |
| select() | SQLのselect句とほぼ一緒。利用したい列を選択。 |
| mutate() | SQLのselect句と似てる。追加の列を作ったり、window関数のような挙動を実施するときに利用 |
| filter() | SQLのwhere句と一緒。絞り込みたい行の条件を記載 |
| group_by() | SQLのgroup by句と一緒。集約処理したいカラムを指定。 |
| summarise() | group_by()関数で指定した集約処理で集計処理を実施(sum,n,mean,sd,mid,min等) |
| arrange() | SQLのorder by句と一緒。集約処理したいカラムを指定。 |
| left_join() | SQLのleft join と一緒。パイプ演算子と組み合わせて「%>% left_join(y, by = c(“column” = “column” )といった感じで利用 |
| inner_join() | SQLのinner join と一緒。パイプ演算子と組み合わせて「%>% inner_join(y, by = c(“column” = “column” )といった感じで利用 |
window関数的な挙動するもの
| 関数名 | 内容 |
| row_number | 昇順にランク付け。同じ値がある場合は、最初に来た方を優先 |
| min_rank | 昇順にランク付け。同じ値がある場合は、同じ順位を付ける。gapあり |
| dense_rank | 昇順にランク付ける。同じ値がある場合は、同じ順位を付ける。gapなし |
| percent_rank | min_rankを0~1にリスケールしたもの |
| cume_dist | 累積割合。percent_rankの累積和ではない。 |
| ntile | n個の群に分割する |